
The best LLM quantization method no one talks about
It's not llama.cpp or GPTQ.


Over these past couple months, there are numerous types of quantization method that pop up over and over like llama.cpp. But rarely do we ever hear about the original quanitization method by Tim Dettmers’s bitsandbytes.
bitsandbytes is not a quantization method per se but a wrapper meant to optimize pytorch models to run in 8 bit which is different from something like GPTQ that is a SOTA one shot quantization technique. About two months ago, bitandbytes also added FP4 mixed-precision capabilities which means that models can also be loaded in 4 bit. Let’s break down some pro and cons.
Disclaimer: I do not have a degree in ML or work on ML for a living. I’ve been playing around with LLMs since around davinci-002 and bought a 3090 to learn about running local LLMs cause its fun.
Pros:
Does not require any sort of training data like other methods (GPTQ)
Works for any model that huggingface accelerate supports (which is pretty much majority of models)
No breaking changes. I swear, we get breaking changes once a week for llama.cpp which forces you to re-quantized models.
You don’t have to wait for others to quantize the model for you, just feed in the FP16 in HF (huggingface) format with load-in-4bit
Fast. I don’t get why or how but the token generation is faster than GPTQ or llama.cpp. I get over 20 T/s for 34B in 4-bit.
It just works. I could not get good quality results for code LLaMA using the new GGUF models but using the 34B with load-in-4bit blew me away.
Cons:
CUDA only. You have to pay the premium and buy a NVIDIA card.
It’s all or nothing. If it doesn’t fit in your VRAM, this won’t work since there is no CPU offloading.
You have to store the FP16 model which is significantly larger than a pre-quantized model. The most annoying part is downloading the models since the model can easily be over 40GB.
How do you use it
Accelerate/Transfomers
model = AutoModelForCausalLM.from_pretrained(name, cache_dir='./model/', use_auth_token=auth_token, torch_dtype=torch.float16, rope_scaling={"type": "dynamic", "factor": 2}, load_in_4bit=True)text-generation-ui
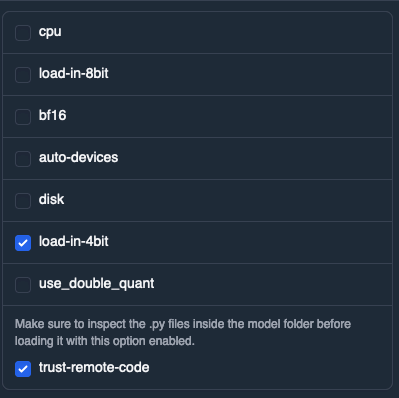
One of TheBloke README mentions to turn on `trust-with-remote-code` but it didn’t seem to change anything for me.
Under the models tab:
Some Code LLaMA and LLamA 2 tips:
If you’re using the instruct model, make sure you are in instruct mode.
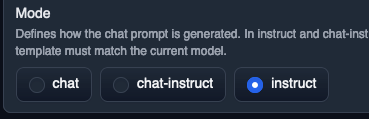
Double check your instruct template or you will get terrible results. I feel like this is the biggest issue with llama.cpp. I still haven’t figured out if I am using the correct prompt for it. But it’s pretty straightforward for text-generation-ui as shown below.
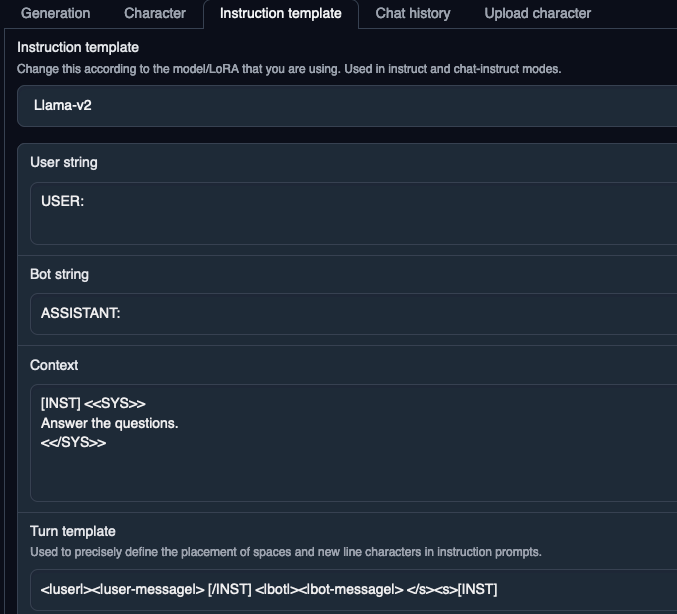
If you’re using LLaMA 2 style models with transformers, I found it really hard to Google the correct prompt even though it looks straightforward in the screenshot above. If you’re using llama_index (it should be easy to adapt to langchain), the prompt is the following:
prompt_template = (
"A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions.\n\n"
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"USER: {query_str}\n"
"ASSISTANT:"
)